Lunch Roulette

Kickstarter’s culture is a core part of who we are as a company and team. Our team hails from a hugely diverse set of backgrounds — Perry was working as a waiter at Diner when he met Yancey, most of our engineers studied liberal arts (myself included — Philosophy), and our community team is made up of former and current projectionists, radio hosts, teachers, funeral directors, chefs, photographers, dungeon masters, artists, musicians, and hardware hackers. Last year, we had the idea to facilitate monthly lunch groups as a way to see if we could accelerate the kind of inter-team mixing that tends to happen in the hallways and between our normal day to day work.
In addition, groups would be encouraged to go for a walk, find a new place in the neighborhood to have lunch, and Kickstarter would pick up the tab.
Shannon, our office manager at the time, and now our Director of HR, had the unenviable job of coming up with all of these lunch groups. The idea was to make them pseudo-random, so that staff wouldn’t end up having lunch with the person they sat next to every day, and that, ideally, they’d meet people they’d never normally interact with as part of their day to day responsibilities.
And, as our headcount has grown — we’ve hired half of Kickstarter between February 2013 and now — we also hoped that these lunches could introduce new staff to old.
But Shannon quickly discovered that creating multiple sets of semi-random yet highly-varied lunch groups was not a trivial task!
One of the biggest issues with keeping groups interesting was moving a person from one group to another meant a cascade of changes which were tedious, and sometimes impossible to reconcile by hand.
So, after spending an entire weekend churning out six possible sets of a dozen groups of 4 people each, Shannon took me up on my offer to help build a formal algorithm to help automate what we had been calling Lunch Roulette.
We put together a meeting and sketched out some constraints that a minimally viable Lunch Roulette generator would have to satisfy:
- Lunch groups should be maximally varied — ideally everyone in a group should be from a different team
- Groups should avoid repeating past lunches
- We should be able to define what it means for a group to be varied
- It should output to CSV files and Google Docs
After a couple weeks of hacking together an algorithm in my spare time, I arrived at something that actually worked pretty well — it’d take a CSV of staffers and spit out what it thought were a set of lunch groups that satisfied our conditions.
We’ve been using it for over 6 months to suggest hundreds of lunch groups and have been pretty happy with the results, and today I’m open sourcing it. But first, a little more about the algorithm.
The Fun Part is How Lunch Roulette Works
Lunch Roulette creates a set of lunches containing all staff, where each group is maximally varied given the staff’s specialty, their department, and their seniority.
It does this thousands of times, and then ranks sets by their overall variety. Finally, the set of lunch groups with highest total variety wins.
Command Line App
Lunch Roulette is a command line application that always requires a CSV file with staff “features”, such as their team and specialty and start date. It is run using the ruby executable and specifying the staff via a CSV file:
ruby lib/lunch_roulette.rb data/staff.csvFeatures are things like the team that a staffer is on, or the day they started. These features can be weighted in different ways and mapped so that some values are “closer” to others.
Along with specifying the various weights and mappings Lunch Roulette users, configurable options include the number of people per group, the number of iterations to perform, and the number of groups to output:
A Dummy Staff
So that you can run Lunch Roulette out of the box, I’ve provided a dummy staff (thanks to Namey for the hilariously fake names) dataset in data/staff.csv:
The use of a CSV input as opposed to a database is to facilitate easy editing in a spreedsheet application (a shared Google Doc is recommended) without the need for migrations or further application bloat. This allows non-engineers to add new staff, collaborate, and add new columns if needed.
Accordingly, the date format of MM/DD/YYYY is specific to common spreadsheet programs like Google Docs and Excel.
Note: There’s a difference between team and specialty. While you and another person might have the same specialty, you might be on different teams. By default Lunch Roulette puts precedence on preventing two people with the same specialty from having lunch, since you probably work closer together than people on the same team. The previous_lunches column contains a double quoted comma-delimited list of previous lunches each having their own ID. If no previous lunches have taken place, then ids will be generated automatically (see the CSV Output section below for more info). All users need to have a user_id to help Lunch Roulette, but this can be an arbitrary value for now.
Configuring Lunch Roulete
Mappings
At the minimum, Lunch Roulette needs to know how different individual features are from each other. This is achieved by hardcoding a one dimensional mapping in config/mappings_and_weights.yml:
team_mappings:
Community Support: 100
Community: 90
Marketing: 80
Communications: 70
Operations: 50
Product: 40
Design: 30
Engineering: 20
Data: 0
specialty_mappings:
Backend: 0
Data: 20
Frontend: 30
Mobile: 50
Finance: 100
Legal: 120
weights:
table: 0.6
days_here: 0.2
team: 0.9
specialty: 0.1
min_lunch_group_size: 4Lunch Roulette expects all employees to have a team (Community, Design, etc.), and some employees to have a specialty (Data, Legal), etc.
Caveat Mapper
These mappings are meant to provide a 1-dimensional distance metric between teams and specialities. Unfortunately, the results can come out a little arbitrary — e.g., why is Community so “far” away from Engineering? I have some notes below about how I might fix this in future versions, but this approach seems to work well enough for now given the intent of Lunch Roulette. Having put a lot of thought into the best strategy for quantizing how teams and colleagues may differ, I’ll say that almost all solutions feel unpalatable if you think about them too hard.
Weights
You should also specify the weights of each feature as a real value. This allows Lunch Roulette to weight some features as being more important than others when calculating lunch group variety. In the supplied configuration, team is weighted as 0.9, and is therefore the most important factor in determining whether a lunch group is sufficiently interesting.
weights:
table: 0.6
days_here: 0.2
team: 0.9
specialty: 0.1It’s not strictly necessary to keep the weights between 0 and 1, but doing so can keep scores more comprehensible. Finally you can specify the default minimum number of people per lunch group:
min_lunch_group_size: 4When the number of total staff is not wholly divisible by this number, Lunch Roulette randomly assigns remaining staff to groups. For example, if a staff was comprised of 21 people, and the minimum group size was 4, Lunch Roulette would create four groups of four people, and one group of five people.
Determining Mappings
The weights that Lunch Roulette uses to calculate team variety are specified in the config/weights_and_mappings.yml file. Team and specialty mappings effectively work as quantizers in the Person class, and if you add new features, you’ll have to modify it accordingly.
For example, Community may be culturally “closer” to the Communications team than the Engineering team. I highly recommended that you tweak the above mappings to your individual use. Remember, the more you define similarity between teams and specialties the easier it is for Lunch Roulette to mix people into varied lunch groups. Seniority is calculated by subtracting the day the employee started from today, so staff that start earliest have the highest seniority. Not all staff are required to have values for all features. In particular, if each staff has a specialty, Lunch Roulette may have a difficult time creating valid lunch sets, so it’s recommended that no more than 30–40% have specialties.
Previous Lunches and Validations
Before Lunch Roulette calculates a lunch group’s variety, the LunchSet class attempts to create a set of lunches that pass the validations specified in the class method valid_set. For a staff of 48 people with a minimum group size of 4, a set would contain a dozen group lunches. Out of the box, there are three validations Lunch Roulette requires for a set to be considered valid:
- The set cannot contain any group where 3 or more people have had lunch before
- The set cannot contain more than one executive (a dummy previous lunch with the id of 0 is used here)
- The set cannot contain anyone with the same specialty (remember, specialties are different than teams)
In most scenarios with at least one or two previous lunches, it is impossible to create a valid lunch set without at least one group having one pair of people who have had lunch before.
Choosing a Set
Remember, the set with the most heterogeneous lunch groups win. variety is first calculated within groups, and then across sets. The set with the highest variety wins.
Group variety
Once a valid lunch set is created Lunch Roulette determines the variety of each group within the set thusly:
- Choose a feature (e.g. we will try to mix a lunch group based on which teams people come from)
- Choose a person
- Normalize the value of that person’s quantized feature value against the maximum of the entire staff
- Do this for all people in the current group
- Find the standard deviation of these values
- Multiply this value by the configured weight
- Repeat this process for all features
- The group score is the sum of these numbers
The resulting average is a representation of the how different each member of a given group is from each other across all features and can be seen in the verbose output:
Tony Reuteler (Design, Table 2),
Campbell Russell (Community, Table 2),
Idella Siem (Product Manager, Table 2),
Fred Pickrell (Community, Table 3)
Emails:
tony@cyberdyne.systems,
campbell@cyberdyne.systems,
idella@cyberdyne.systems,
fred@cyberdyne.systems
Sum Score: 0.4069
Score Breakdown: {
"table"=>0.075,
"days_here"=>0.04791404160231572,
"team"=>0.28394541729001366,
"specialty"=>0.0
}The higher the sum, the more varied that particular lunch group.
Set variety
Since all sets will have the same number of groups in them, we can simply sum the average scores across all the groups and generate at a per-set score. This represents the average variety across all groups within a set and is used to compare sets to each other.
Formally
I was interested in how Lunch Roulette could be represented formally using math, so I asked my colleague Brandon — Kickstarter’s math-PhD-refugee-iOS-dev — for some help. After some beers and a whiteboard session, we arrived at at decent generalization of what’s happening under the hood. It should be noted that any errors in the following maths are entirely my fault and any brilliance should be entirely ascribed to Brandon’s patient insights.
Let S be the set of staff and 𝒰 be the set of all partitions of S into N groups. Since 𝒰 is very large, we narrow it down by throwing out lunches that we consider boring. For example, no lunch groups with 3 or more people who have had lunch before, etc.
Then we are left with 𝒰ʹ, which is the subset of 𝒰 of valid lunches.
We define a “feature” of the staff to be a integer-valued function on S, i.e. f : S → ℤ.
For example, the feature that differentiates teams from each other might assign 15 to someone on the Community, and 30 to someone on the operations team.
It’s important to note that this number doesn’t represent anything intrinsic about the team: it’s merely an attempt at mapping distance (albeit one-dimensionally) between teams. Future versions of Lunch Roulette should probably switch this to a function returning a vector of values encoding multi-dimensional characteristics about teams (e.g. [0,1,0,1,1,1,0]).
Let’s fix M such features, f_i : S → ℤ. For a given feature f, let us define: ||f|| = max_(s ∈ S) f(s).
We need ||f|| so that we can normalize a given feature’s value against the maximum value from the staff.
It is also useful to apply weights to features so that we can control which features are more important. Let W_i ∈ [0,1] be the set of weights for each feature i=1, …, M.
Then we maximize the variety among lunch groups thusly:
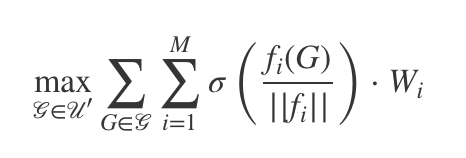
In english, that’s: for each feature inside each group, we normalize a person’s value to the maximum value found in the staff, then calculate the standard deviation (σ).
Then, all σ are added up for the group and then multiplied by the weight given to the feature to achieve an overall variety metric for a given group. The sum of those σ’s inside a set represents its overall variety.
Here’s the inner loop (representing the innermost Σ above) in LunchGroup which calculates a given group’s score:
def calculate_group_score
h = features.map do |feature|
s = @people.map do |person|
person.features[feature] / config.maxes[feature].to_f
end.standard_deviation
[feature, s * config.weights[feature]]
end
@scores = Hash[*h.flatten]
endLunch Roulette does this thousands of times, then plucks the set with the highest overall score (hence the max) and saves that group to a CSV.
I’ve since discovered that lunch roulette is a version of a “Maxmimally Diverse Grouping Problem”, and it seems like some researchers from The University of Valencia in Spain have built some similar software to Lunch Roulette in Java using a couple different methods for maximizing diversity.
Gut Testing Lunch Roulette
If specified, Lunch Roulette will output the top N results and/or the bottom N results. This is useful for testing its efficacy: if the bottom sets don’t seem as great as the top sets, then you know its working! This will output 2 maximally varied sets, and two minimally varied sets:
ruby lib/lunch_roulette.rb -v -m 2 -l 2 data/staff.csvIf you wanted to get fancy, you could set up a double blind test of these results.
CSV Output
Unless instructed not to, Lunch Roulette will generate a new CSV in data/output each time it is run. The filenames are unique and based off MD5 hashes of the people in each group of the set. Lunch Roulette will also output a new staff CSV (prefixed staff_ in data/output) complete with new lunch IDs per-staff so that the next time it is run, it will avoid generating similar lunch groups. It is recommended that you overwrite data/staff.csv with whatever version you end up going with. If used with the verbose option, Lunch Roulette will dump a TSV list of staff with their new lunches so you can paste that back into Google Docs (pasting CSVs with commas doesn’t seem to work).
Take It For a Spin
I’ve open sourced Lunch Roulette and it’s available on GitHub under a MIT license.
Thanks
Lunch Roulette went from a not-entirely serious side project into something much more interesting and now, I hope, something possibly useful for others. But I couldn’t have done it without Shannon Ferguson having done all of the work manually, and Brandon Williams helping me with the math.
Please consider forking it and letting us know if you use it.
Happy Lunching!
Written by Fred Benenson.

